JS 中的二进制,不仅仅于JS

进制数的表示
进制数字面量
- 二进制 0b 或 0B 前缀,如 0b11 === 3
- 八进制 0o 或 0O 前缀,如 0o11 === 9
- 十六进制 0x 或 0X 前缀,如 0x11 === 17
二进制数的表示法
以八个二进制位的举例。
原码
第 1 位表示符号位,0 表示正数,1 表示负数。后 7 位表示真值。
0000 0010 // 2 原码
1000 0010 // -2 原码
反码
对于正数:是其原码本身不变。
对于负数:符号位不变,后 7 位的真值按位取反。
0000 0010 // 2 原码
0000 0010 // 2 反码
1000 0010 // -2 原码
1111 1101 // -2 反码
补码
对于正数:是其原码本身不变。
对于负数:在原码的基础上,取其反码,再加 1。
0000 0010 // 2 原码
0000 0010 // 2 反码
0000 0010 // 2 补码
1000 0010 // -2 原码
1111 1101 // -2 反码
1111 1110 // -2 补码
以上结论就是,正数的表示法都一样,负数则不同。
为什么会有反码、补码的存在?
为了减少计算机运算逻辑的复杂度,所以将符号位也加入运算,补码的表示可以做到只用加法就进行加减法的运算。
// 1 + 2 补码运算
0000 0001 + 0000 0010 = 0000 0011
0000 0011(补码) = 0000 0011(反码) = 0000 0011(原码) = 3
// 1 + (-2) 补码运算
0000 0001 + 1111 1110 = 1111 1111
1111 1111(补码) = 1111 1110(反码) = 1000 0001(原码) = -1
进制转换
十进制转其他进制
toString
6..toString(2) // '110'
9..toString(8) // '11'
其他进制十进制转
parseInt
parseInt('110', 2) // 6
parseInt('11', 8) // 9
Number
Number('0b110') // 6
Number('0o11') // 9
+(一元运算符)
+'0b110' // 6
+'0o11' // 9
二进制的位运算
位运算符将它的操作数视为 32 位元的二进制串数。 位运算符在此表示上执行运算。JavaScript 数值。
JS 位运算符
按位与(&)
a & b:在 a,b 的位表示中,每一个对应的位都为 1 则返回 1,否则返回 0。
// 2 & 6 = 2
010
110
---
010
妙用:
- 判断奇偶 n&1
按位或(|)
a | b:在 a,b 的位表示中,每一个对应的位,只要有一个为 1 则返回 1,否则返回 0。
// 2 | 6 = 6
010
110
---
110
按位异或(^)
a ^ b:在 a,b 的位表示中,每一个对应的位,不相同则返回 1,相同则返回 0。
// 2 ^ 6 = 4
010
110
---
100
妙用:
- 交换数值 diff = a^b; b = a^diff; a = b^diff
按位非(~)
~a:反转被操作数的位
// ~6 = -7
0000 0110
---
1111 1001 // 反转后 = 补码
1111 1000 // 反码
1000 0111 // 原码
妙用:
- ~~value 取整数,比 parseInt(value)效率更高
左移(<<)
a << b:将 a 的二进制串向左移动 b 位,右边移入 0
// 6 << 2 = 24
0000 0110
---
0001 1000
// -6 << 2 = -24
1000 0110
---
1001 1000
妙用:
- a << n = a * 2^n
算术右移(>>)
a >> b:把 a 的二进制表示向右移动 b 位,丢弃被移出的所有位
// 6 >> 2 = 1
0000 0110
---
0000 0001
// -6 >> 2 = -2
1000 0110 // 原码
1111 1001 // 反码
1111 1010 // 补码
1111 1110 // 右移2位
1111 1101 // 右移后反码
---
1000 0010 // 移位后原码
妙用:
- a >> n = a / 2^n (a 为正数)
- a >> n = (a + 2^32) / 2^n (a 为负数)
无符号右移(>>>)
a >>> b:把 a 的二进制表示向右移动 b 位,丢弃被移出的所有位,并把左边空出的位都填充为 0
// 6 >>> 2 = 1
0000 0110
---
0000 0001
// -6 >>> 2 = 1073741822
10000000 00000000 00000000 00000110 // 32位原码
11111111 11111111 11111111 11111001 // 反码
11111111 11111111 11111111 11111010 // 补码
00111111 11111111 11111111 11111110 // 移位
---
00111111 11111111 11111111 11111110 // 移位后原码
位运算有什么意义?
位运算能够高效率的完成数值的计算。
因为机器最终是转化为二进制去运算,位运算过程则更为直接。底层使用补码运算加法和移位,实现不仅仅加法的其他运算(减乘除模法等)。
💡虽然位运算妙用更简洁更高效,但是不建议在业务代码中组合使用,会影响可读性。位运算更适合用在一些性能要求高的底层逻辑代码。
位掩码
位掩码(BitMask),是”位(Bit)“和”掩码(Mask)“的组合词。”位“指代着二进制数据当中的二进制位,而”掩码“指的是一串用于与目标数据进行按位操作的二进制数字。
位掩码就是位运算的一个应用场景。
举一个例子:一个4位二进制的权限值,依次对应 新增、删除、修改、查询 。
let createFlag = 0b1000
let deleteFlag = 0b0100
let modifyFlag = 0b0010
let queryFlag = 0b00001
let permission = 0b0000 // 权限初始值
// 更改 '删除' 的权限
permission = permission ^ deleteFlag // 0b0100
// 更改 '查询' 的权限
permission = permission ^ queryFlag // 0b0101
// 读取
const allowDelete = Boolean(permission & deleteFlag) // true
const allowQuery = Boolean(permission & queryFlag) // true
const allowModify = Boolean(permission & modifyFlag) // false
二进制缓冲区
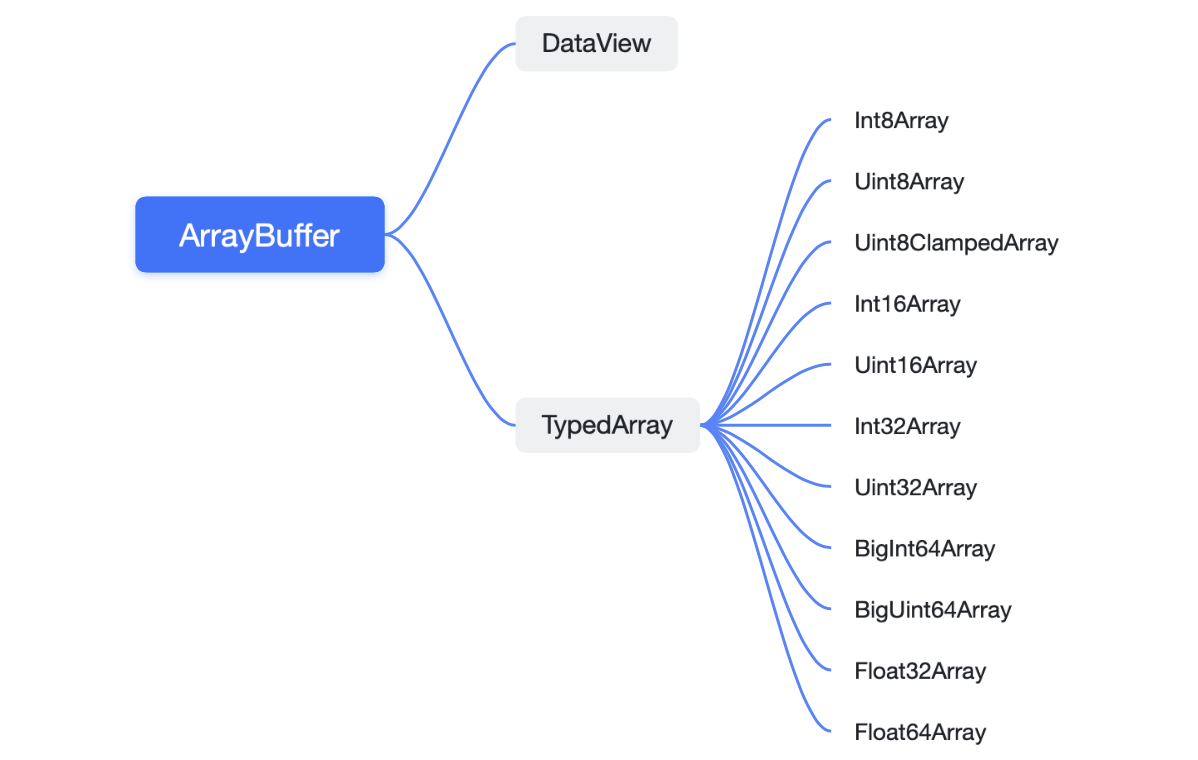
ArrayBuffer
固定长度的原始二进制数据缓冲区(字节数组)。不能直接操作,只能通过类型视图(DataView、TypedArray)操作。
构造函数传参一个长度,创建以字节(8 位)为单位的数组。
// 8位 * 16字节 = 128位
const buffer = new ArrayBuffer(16);
// 128位 / 8位 = 长度16
const i8 = new Int8Array(buffer)
console.log(i8.length) // 16
// 128位 / 32位 = 长度4
const i32 = new Int32Array(buffer)
console.log(i32.length) // 4
TypedArray
作为 ArrayBuffer 类型化的视图,提供方便地读写二进制数据的操作。TypedArray - JavaScript | MDN
初始化接收 固定长度或原始 buffer 数组,以对应的类型数组的设置范围内写入和读取。
Uint8Array
数组每个元素大小为一个字节,值范围 0 到 255,无符号的整型(正整数)
const u8 = new Uint8Array(6)
u8[0] = 100
u8[1] = 300
console.log(u8[0]) // 100
console.log(u8[1]) // ?(越界赋值会怎么样)
// 解析:
DataView
是一个可以从 ArrayBuffer 对象中读写多种数值类型的底层接口视图。 DataView - JavaScript | MDN
const buffer = new ArrayBuffer(32)
const dv = new DataView(buffer)
dv.setInt8(0, 100)
dv.setInt16(1, 200)
console.log(
dv.getInt8(0), // 100
dv.getInt16(0), // ?(Int16 取 Int8)
dv.getInt8(1), // 0
dv.getInt16(1), // 200
)
// 解析:
二进制编码
编码类型
- ASCII
是一种基于拉丁字母的字符编码标准,用于电子通信。它最初是美国信息交换标准代码,使用 7 位二进制数来表示 128 个字符。 ASCII-wiki
特征:仅表示英文及其符号;一个字符占用了一个字节,但是实际用了 7 位,第一位始终在为 0。
- Unicode
是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 使用两个字节来表示一个字符,可以表示几乎所有的语言文字。
特征:是一种编码方式;UCS-2(unicode 的标准实现)占用两个字节,但有一些字符实际只使用了一个字节。
- UTF-8
是一种针对 Unicode 的可变长度字符编码。它使用一至四个字节来表示每个字符,节省了存储空间,也方便了传输。

- Base64
是一种用于传输二进制数据的编码方式,可以将任意二进制数据编码成可打印字符,便于传输和处理。
base64 要求将每三个 8bits 字节转换为四个 6bit 的字节,再根据这 4 个字节的十进制在索引表中查找对应的值。
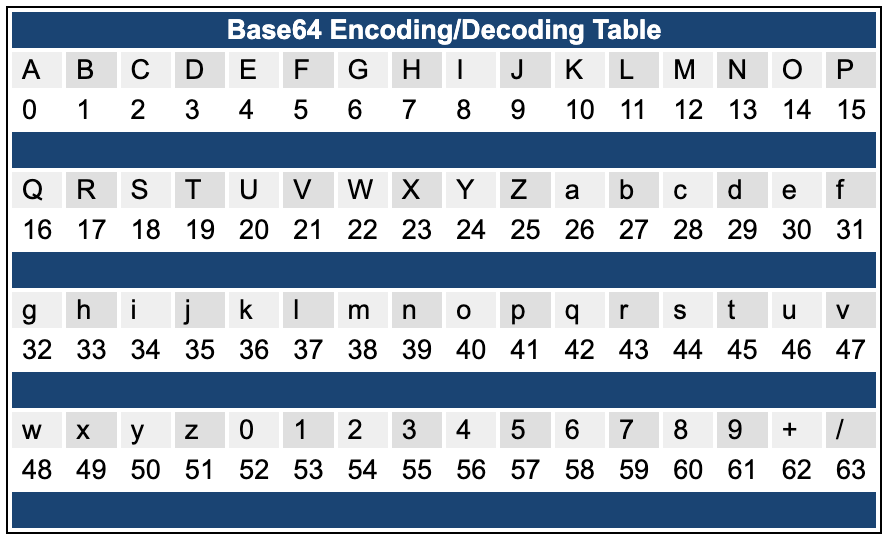
The Base64 algorithm description
JS 的字符编码方法
charCodeAt 与 fromCharCode
charCodeAt 返回一个字符的 unicode 编码(与 ASCII 重合的字符则一致)。
fromCharCode 返回 unicode 编码对应的字符。
const char = '编码'
const charcode = [char.charCodeAt(0), char.charCodeAt(1)]
console.log(charcode)
// [32534, 30721]
console.log(String.fromCharCode(...charcode))
// '编码'
TextEncoder 与 TextDecoder
TextEncoder 把字符转为 UTF-8 的字节流。
TextDecoder 则解码对应的字节流为字符。
const encoder = new TextEncoder()
const view = encoder.encode('编码')
console.log(view)
// [231, 188, 150, 231, 160, 129]
const decoder = new TextDecoder()
const chars = decoder.decode(view)
console.log(chars)
// '编码'
const u8 = new Uint8Array(3)
encoder.encodeInto('编码', u8)
console.log(u8) // [231, 188, 150]
console.log(
decoder.decode(u8), // '编'
)
atob 与 atob
btoa 将字符串编码为 base64(仅支持 ascii 字符,不支持其他如中文)。
atob 解码 base64 编码的字符串。
const charsEn = 'base64'
const base64En = btoa(charsEn)
console.log(base64En) // 'YmFzZTY0'
console.log(atob(base64En)) // 'base64'
const charsZh = '编码'
const base64Zh = btoa(encodeURIComponent(charsZh))
console.log(base64Zh) // 'JUU3JUJDJTk2JUU3JUEwJTgx'
console.log(
decodeURIComponent(atob(base64Zh)), // '编码'
)
二进制的应用
上传下载
Ajax、Fetch 和 WebSocket 接收和上传 arraybuffer 二进制数组
图像、视频音频处理
canval、webGL、blob 等
协议
如 protobuf 等
Links
参考文章
- 原码, 反码, 补码 详解 - ziqiu.zhang - 博客园
- 聊聊 JavaScript 中的二进制数
- 【javaScript】Javascript 中的 位运算符 + 使用场景 + 性能对比 + 封装_@Umbrella 的博客-CSDN 博客`